Table of Contents:
- 그라디언트 점검 (Gradient checks)
- 제대로 돌아가는지 확인하기 (Sanity checks)
- 학습 과정 돌보기 (Babysitting the learning process)
- 파라미터 업데이트 (Parameter updates)
- 초-파라미터 최적화 (Hyperparameter Optimization)
- 평가 (Evaluation)
- 요약
- 추가적인 참고 문헌
Learning
이전 섹션들에서는 레이어를 몇 층 쌓고 레이어별로 몇 개의 유닛을 준비할지(newwork connectivity), 데이터를 어떻게 준비하고 어떤 손실 함수(loss function)를 선택할지 논하였다. 말하자면 이전 섹션들은 주로 뉴럴 네트워크(Neural Network)의 정적인 부분인데, 본 섹션에서는 동적인 부분들을 소개한다. 파라미터(parameter)를 학습하고 좋은 초-파라미터(hyperparamter)를 찾는 과정 등을 다룰 예정이다.
그라디언트 체크 (Gradient Checks)
이론적인 그라디언트 체크라 하면, 수치적으로 계산한(numerical) 그라디언트와 수식으로 계산한(analytic) 그라디언트를 비교하는 정도라 매우 간단하다고 생각할 수도 있겠다. 그렇지만 이 작업을 직접 실현해 보면 훨씬 복잡하고 뜬금없이 오차가 발생하기도 쉽다는 것을 깨달을 것이다. 이제 팁, 트릭, 조심할 이슈들 몇 개를 소개하고자 한다.
같은 근사라 하여도 이론적으로 더 정확도가 높은 근사 공식이 있다 (Use the centered formula). 그라디언트()를 수치적으로 근사한다 하면 보통 다음 유한 차분 근사(finite difference approximation)를 떠올릴 것이다:
여기서 는 아주 작은 수이고 보통 1e-5 정도의 수를 사용한다. 위 식보다는 아래의 중심화된(centered) 차분 공식이 경험적으로는 훨씬 낫다:
물론 이 공식은 말고도 도 계산하여야 하므로 최초 식보다 계산량이 두 배 많지만 훨씬 정확한 근사를 제공한다. 및 의 ( 근방에서의) 테일러 전개를 고려하면 이유를 금방 알 수 있다. 첫 식은 의 오차가 있는 데 반해 두번째 식은 오차가 이다 (즉, 이차 근사이다). – 역자 주 : (1) 테일러 전개에서 로부터 . (2) 가 보통 벡터이므로 보다는 가 더 정확한 표현이나 편의상 을 생략한 듯 보입니다.
상대 오차를 사용하라 (Use relative error for the comparison). 그라디언트의 (수식으로 계산한, analytic) 참값 와 수치적(numerical) 근사값 을 비교하려면 어떤 디테일을 점검하여야 할까? 이 둘이 비슷하지 않음(not compatible)을 어떻게 알아낼 수 있을까? 가장 쉽게는 둘의 절대 오차 혹은 그 제곱을 쭉 추적하여 이 값(들)이 언젠가 어느 한계점(threshold)를 넘으면 그라디언트 오류라 할 수도 있겠다. 그렇지만 절대 오차에는 문제가 있는 것이, 가령 절대 오차가 1e-4라 가정하여 보자. 만약 와 모두 1.0 언저리라면 1e-4의 오차 정도는 매우 훌륭한 근사이고 이라 할 수 있다. 그런데 만약 두 그라디언트가 1e-5거나 더 작은 값이라면? 그렇다면 1e-4는 매우 큰 차이가 되고 근사가 실패했다고 보아야 한다. 따라서 절대 오차와 두 그라디언트 값의 비율을 고려하는 상대 오차가 더 적절하다. 언제나!:
보통의 상대 오차 공식은 분모에 혹은 둘 중 하나만 있지만, 나는 둘의 최대값을 분모로 선호하는 편이다. 그래야 공식에 대칭성이 생기고 둘 중 하나가 exactly 0이 되어 분모가 0이 되는 사태를 방지할 수 있다 (ReLU를 사용하면 자주 일어나는 문제이다). 와 가 모두 exact 0이 된다면? 이 때는 상대 오차를 점검할 필요 없이 그라디언트 체크를 통과하여야 한다. 당신의 코드가 이 상황을 감안하여 조직된 코드인지 점검하여 보라.
실제 상황에서의 유용한 가이드:
- (상대 오차) > 1e-2 면 그라디언트 계산이 아마 잘못되었을 수도 있다.
- 1e-2 > (상대 오차) > 1e-4 면 불편함을 느끼기 바란다.
- 1e-4 > (상대 오차) 는, 꺾임이 있는 목적함수 (objectives with kinks)에서는 괜찮다. 그렇지만 tanh 혹은 softmax를 쓰는 목적함수처럼 꺾임이 없다면 1e-4는 너무 크다.
- 1e-7 혹은 그보다 작은 상대 오차라면, 행복을 느껴야 한다.
하나 더 유념해야 할 것은, 망의 레이어 개수가 많아지면(deeper network) 상대 오차가 커진다. 이를테면 레이어(layer) 10개짜리 망(network)에서 인풋 데이터의 그라디언트를 체크한다면, 에러가 층을 올라가며 축적되므로 1e-2 정도의 상대 오차는 괜찮을 수도 있다. 거꾸로 말하자면, 미분가능한 함수 하나만 갖고 노는데 1e-2의 상대 오차가 발생한다면 이것은 부정확한 그라디언트일 가능성이 매우 높다.
이중정확성 변수를 사용하라 (Use double precision). 흔히들 실수하는 것이, 그라디언트 체크를 계산하는 데 단일정확성 부동소숫점(single precision floating point) 변수를 사용하는 경우가 있다. 단일정확성 변수를 쓰면 그라디언트 계산이 맞다 하더라도 상대 오차가 (1e-2 정도로) 커지는 경우가 종종 있다. 내 경험상으로는 이중정확성 변수를 쓰면 상대 오차가 1e-2에서 1e-8까지 개선되는 경우도 봤다.
부동소숫점 연산이 활성화되는 범위에서 계산하라 (Stick around active range of floating point). 당신 좀더 세심한 코드를 작성하고 실수를 줄이려면 “모든 컴퓨터 사이언티스트들이 부동소숫점 연산에 대해 알아야 하는 것들(What Every Computer Scientist Should Know About Floating-Point Arithmetic)” 를 읽는 게 좋다. 예를 들어, 신경망에서는 손실함수(loss function)를 배치별로(over batch)로 normalize하는 것이 보통이다 (역자 주 : 그라디언트 합을 배치 사이즈로 나누는 장면을 지칭하는 듯). 그렇지만 한 자료당(per datapoint) 그라디언트가 매우 작다면, 거기에 또 데이터 갯수를 부가적으로 나눌 경우 매우 작은 수가 되고 더욱더 많은 수치적인 문제가 생길 수 있다. 그래서 필자는 혹은 의 계산값을 계속 찍어보고 두 값이 너무 작지 않은가 확인하는 편이다. (대충 1e-10 혹은 그보다 작은 크기의 값이면 걱정하여라) 만약 두 값이 너무 작다면, 적당히 상수를 곱하여 부동소숫점 표현이 조금 더 “괜찮도록” (부동소숫점 표현에서 지수 부분이 0이 되도록) 만들 수도 있다.
목적함수에서의 꺾인 점 (Kinks in the objective). 꺾인 점(kink)들에서 부정확한 계산이 발생할 수 있는데 이를 그라디언트 체크 과정에서도 염두에 두고 있어야 한다. 꺾인 점(kink)은 목적함수의 미분 불가능한 부분을 지칭하는 용어이다. ReLU 함수 (), 서포트 벡터 머신(SVM) 목적함수나 맥스아웃 뉴런(maxout neuron) 등을 사용하면 발생할 수 있다. 꺾인 점이 야기시킬 수 있는 문제는 대략 이렇다. ReLU 함수의 그라디언트를 에서 체크한다고 생각하여 보자. 이므로 는 정확히 이다. 그렇지만, 수치적으로 계산된 그라디언트는 가 꺾인 점을 넘을 수도 있으므로 (이를테면 인 경우) 갑자기 이 아닌 값을 내놓게 될 수도 있다. 이런 병적인(?) 경우까지 신경써야 하냐고 물을 수도 있겠는데, 사실 매우 흔하다. 예를 들어 CIFAR-10를 위해 서포트 벡터 머신(SVM)을 쓴다고 하면, 데이터가 50,000개이고(50,000 examples) 한 데이터당 항이 9개씩 있으니 결국 45만개의 ReLU항과 맞닥뜨리게 된다. 게다가 서포트 벡터 머신 분류기(SVM classifier)와 신경망(neural network)을 붙이면 ReLU들 때문에 꺾인 점이 더 늘어날 수도 있다.
다행히도, 손실함수를 계산할 때 꺾인 점을 넘어서 계산했는지 (a kink was crossed) 여부를 알 수 있다. 꼴 함수에서 , 중 누가 “이겼는지”를 계속 기록해둔다고 생각해 보자. 와 를 계산할 때 적어도 하나의 “승자”가 바뀐다면, 꺾인 점을 넘는 현상이 발생한 것이고 그렇다면 수치적인 그라디언트가 정확한 값이 아닐 수도 있다.
적은 수의 데이터만 써라 (Use only few datapoints) 꺾인 점과 관련된 하나의 해결책은 더 적은 데이터를 쓰는 것이다. 손실함수가 꺾인 점을 포함하고 있으면 (ReLU나 margin loss등을 썼을 경우처럼) 데이터가 적을수록 더 적은 꺾인 점을 포함할 것이고, 따라서 유한 차분 근사(finite different approximation) 과정에서 꺾인 점을 가로지르는 경우가 더 적을 것이다. 게다가, ~2 혹은 3개의 데이터에 대해서만 그라디언트 체크를 수행하는 게 거의 배치(batch) 전부에 대해 그라디언트 체크하는 게 될 테니 훨씬 빠르고 효율적이다. (역자 주 : 그렇지만 배치 사이즈가 작아지면 다른 쪽에서 문제가 생길 수도 있을 것 같은데..)
Step size h에 주의하라. 꼭 작을 수록 좋은 건 아닌 게, 가 훨씬 작으면 수치적인 정확도(numerical precision) 문제에 부딪힐 수 있다. 가끔 그라디언트 체크가 잘 안 되면, 를 1e-4나 1e-6 정도로 조정하여 보라. 갑자기 될 수도 있다. 링크된 위키피디아 기사에는 h에 따른 수치적 그라디언트 오차가 xy-plot으로 조사되어 있다.
“특징적인” 연산이 수행되는 곳에서 그라디언트 체크를 (Gradcheck during a “characteristic” mode of operation). 그라디언트 체크는 파라미터 공간(parameter space)의 특정한 (보통 랜덤인) 점 위에서 수행됨을 기억하자. 그라디언트 체크가 한 점에서는 성공한다 하여도 다른 점에서 맞게 수행되리라고는 믿기 힘들다. 게다가, 초기값을 랜덤하게 줄 경우(random initialization) 그 점은 파라미터 공간의 가장 “특징적인(characteristic)” 점이 아닐 수도 있고, 분명 제대로 코딩(implement)된 듯한 그라디언트가 사실 잘 계산되지 않는 병적인 상황을 야기할 수도 있다. 예를 들어, SVM에서 초기 웨이트값을 매우 작게 설정하면, 모든 데이터 포인트에 거의 0에 근접한 점수를 부여할 것이고 그라디언트 값들 또한 모든 데이터에 걸쳐 어떤 패턴을 나타낼 것이다. 만약 그라디언트 구현이 잘못되었다면 이 패턴을 계속 만들어낼 것이고 좀더 특징적인 계산으로 (e.g. 몇몇 점수가 다른 것보다 큰 경우) 일반화하지 못할 수도 있다. 그러므로, 안전하게 가려면, 네트워크가 학습을 시작할 무렵 짧은 번인(burn-in)을 이용하고, 손실(loss)가 하강하기 시작한 뒤에 그라디언트 체크를 수행하는 것이 최선이다. 요컨대, 첫번째 iteration에서부터 그라디언트 체크를 수행하면 그 때만의 병적인(pathological) 오류 때문에 우리가 정말로 정확하게 그라디언트 체크를 수행하는 부분에서의 오류를 놓칠 수도 있다.
정규화가 데이터를 압도하게 하지 마라 (Don’t let the regularization overwhelm the data). 가끔, 손실함수(loss function)는 데이터 손실과 정규화(regularization) 손실 (e.g. 웨이트값(weight)들에 대한 L2 벌점(penalty))의 합으로 이루어져 있다. 하나 알고 있어야 하는 위험은, 정규화 손실이 데이터 손실을 압도할 수 있다는 것인데, 이 경우 그라디언트는 주로 (그라디언트 표현이 훨씬 간단한) 정규화 항(term)에서 올 것이다. 이 경우 데이터 손실 그라디언트가 올바르게 구현되지 못하는 상황을 감출 수도 있다. 그러므로, 먼저 정규화를 끄고 데이터 손실 부분만 체크를 수행하길 추천하며 그 다음에 정규화 항을 따로 점검해 보라. 정규화 항만 따로 어떻게 점검 하냐고? 하나의 방법은 코드를 해킹(hack)하여 데이터 손실 부분을 제거하는 것이다. 다른 방법으로는 정규화 항의 강도(strength)를 높여서 그 효과가 그라디언트 체크 수행시 무시할 수 없게 키운 뒤 (정규화 항 부분에서의) 잘못된 그라디언트가 감지되도록 하라.
드랍아웃과 augmentation을 끄라 (Remember to turn off dropout/augmentations). 그라디언트 체크를 수행하는 동안, 네트워크에서 결정되지 않은(non-deterministic) 효과, 이를테면 드랍아웃(dropout), 임의 자료 확대(random data augmentations), 등을 반드시 꺼 두어라. 당연한 이야기지만 이들을 꺼두지 않으면 수치적 그라디언트 근사에서 대규모의 오차가 생길 수 있다. 이 효과들을 끌 경우 단점은 이들의 그라디언트 체크를 수행할수 없다는 것이다 (e.g. 드랍아웃이 올바르게 역전파(backpropagate)되지 않을 수 있다). 그러므로 and 및 수식으로 계산된(analytic) 그라디언트를 계산하기 전에 시드(seed)를 특정 값으로 고정하는 것이 좀더 나은 해결책일 수도 있다.
몇 개의 차원에서만 체크하라 (Check only few dimensions). 실제 데이터에서 그라디언트는 수백만개의 파라미터값을 가질 수도 있다. 이런 경우엔 오직 몇 차원의 그라디언트들만 체크 하고 다른 것들은 잘 계산되었다고 믿는 것이 현실적일 수도 있다. 조심하라: 모든 ‘분리된 파라미터’들에 대해서 적은 차원의 그라디언트 체크를 수행하라. 몇몇 용례에서는, 사람들이 파라미터들을 편의상 하나의 큰 파라미터 벡터로 결합한다. 이 경우, 이를테면, 편향값(bias)들은 전체 벡터에서 아주 적은 수만 차지하고 있을 수 있으므로, 이를 반영하여 샘플한 뒤 모든 파라미터들이 올바른 그라디언트를 받고 있는지 확인하는 것이 중요하다.
학습 전에: 제대로 돌아가는지 확인하는 팁과 트릭들 (Before learning: sanity checks Tips/Tricks)
풀려는 최적화 문제가 매우 비싸(expensive)지기 전에, 다음 절차들을 돌려볼 만하다.
- 맞는 손실함수를 찾아라 ?? (Look for correct loss at chance performance.)
적은 수의 파라미터로 초기화할 때는 당신이 기대한 손실함수값(loss)를 얻는지 확인하라. 먼저 데이터 손실함수 (data loss) 하나만 확인하는 것이 가장 낫다 (따라서 정규화 강도(regularization strength)는 영으로 설정하여라). 예를 들어, CIFAR-10에 Softmax 분류기를 이용할 경우 초기 손실함수값을 2.302로 기대할 수 있는데, 왜냐하면, -ln(0.1) = 2.302 – 각 클래스에 확률이 0.1로 분산되었을 테고 Softmax 손실함수는 올바른 분류 확률에 음의 로그를 취한 값이기 때문이다. Weston Watkins SVM을 사용할 경우에는, (모든 점수(score)가 어림잡아 0이기 때문에) 고려되는 모든 마진값(margin)이 위반될 테니 9의 손실값을 기대할 수 있다 (마진값은 각각 잘못 분류된 클래스마다 1이다). 이런 손실값들이 나오지 않으면 초기화에 문제가 있을 수 있다. - 두 번째 확인 절차로써, 정규화 강도를 올릴 수록 손실함수값이 올라가야 한다.
- 자료의 작은 부분집합으로 과적합해 보라 (Overfit a tiny subset of data). 마지막으로 가장 중요한 사항인데, 전체 데이터셋으로 훈련을 시작하기 전에, 작은 부분으로 훈련을 시도하여 보고 (한 20개의 자료 정도), 0의 비용(cost)을 달성할 수 있는지 확인하여 보라. 이 실험에서도 역시 정규화 강도는 0으로 설정하는 것이 가장 나으며, 그렇지 않으면 0의 비용을 얻을 수 없을 것이다. 작은 자료에서의 이러한 확인 과정이 제대로 끝나지 않으면 전체 데이터셋으로 나아가는 것은 무가치하다. 하나 강조할 것은, 아주 작은 데이터셋에 성공적으로 과적합하였지만 여전히 코딩(implementation)이 올바르게 이루어지지 않았을 수 있다. 예를 들어, 가지고 있는 데이터 포인트(datapoint)들의 특성(feature)들이 어떤 버그 때문에 임의로(randomly) 선정된 경우, 작은 훈련 집합(training set)에의 과적합은 성공할지라도 그게 전체 데이터셋으로 일반화되지 않을 수도 있다.
학습 과정 돌보기 (Babysitting the learning process)
신경망을 훈련하는 중에 몇몇 쓸모있는 값(quantitity)은 모니터링해야 한다. 이런 도표들은 학습 과정을 지켜보는 창문이다. 좀더 효율적인 학습을 위한 하이퍼파라미터(hyperparameter) 조정도 여기서 직관적 영감을 얻는다.
도표의 x축은 언제나 에폭(epoch)을 단위로 한다. 에폭(epoch)은 각 자료(example)가 몇 번이나 학습(SGD iteration–역자 주)에 사용되었는가를 재는 용어이다. (이를테면 1 에폭이 지났다는 것은 모든 자료가 한 번씩 SGD iteration에 사용되었음을 뜻한다.) x축으로 SGD 알고리즘 반복횟수(iteration)를 할 수도 있겠지만 에폭이 더 선호되는 편이다. 반복 횟수(iteration number)은 배치 사이즈(batch size)의 선택에 따라 임의로 바뀔 수 있기 때문이다.
손실 함수 (Loss function)
손실 함수(loss)는 forward pass 동안 개개의 배치(batch)에서 계산되고 따라서 훈련(training) 과정에서 추적하기 용이하다. 아래는 시간에 따른 손실 그래프의 모양을 여러 학습 속도(learning rate)에 따라 그려본 것이다. 각각의 모양이 시사하는 바도 함께 적었다:
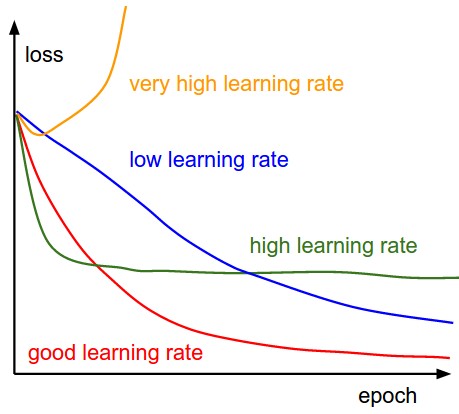
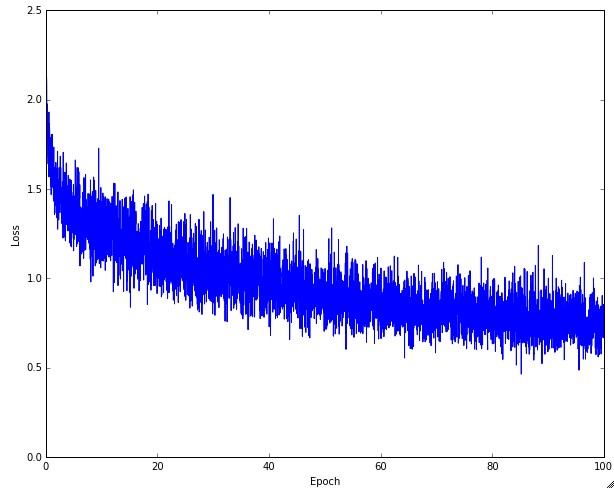
손실 함수의 “씰룩거림”은 배치 사이즈와 연관이 있다. 만일 배치 사이즈가 1이면 훨씬 더 많이 씰룩거릴 것이다. 만일 배치 사이즈가 전체 데이터셋이면 이 씰룩거림은 최소화될 것인데, 왜냐하면 모든 그라디언트 업데이트가 손실함수를 단조적으로 향상시킬 것이기 때문이다 (학습 속도가 너무 크지만 않다면).
어떤 사람들은 손실함수의 로그값의 그래프를 선호하기도 한다. 일반적으로 학습 과정은 어떤 지수적인 모양(하키 스틱 모양)을 취하고 있기 때문에, 로그 손실 그래프는 좀 더 해석이 용이한 직선의 모양처럼 보인다. 부가적인 사항으로, 만약 여러 개의 교차검증 모형(의 손실 그래프)를 같은 그래프 위에 그리면, (로그 손실 그래프로 보면) 그들 사이의 차이가 좀 더 명백해지는 장점이 있다.
가끔 손실 함수 모양이 우스꽝스러울 때도 있다. lossfunctions.tumblr.com.
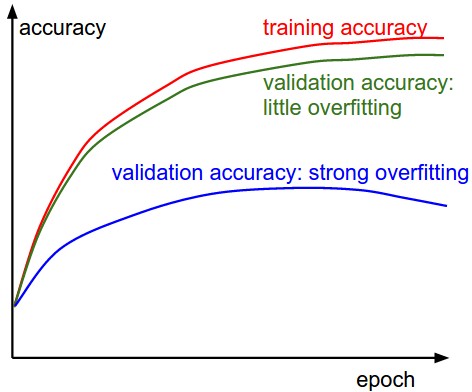
훈련/검증 정확도 (Train/Val accuracy)
훈련/검증 정확도(training/validation accuracy)는 분류기 훈련시 추적해야 할 또다른 중요한 값이다. 이 플롯은 당신의 모형이 과적합(overfitting) 중인지를 발견할 수 있는 값진 인사이트를 제공한다:
웨이트의 현재값과 변화량의 비율 (Ratio of weights:updates)
마지막으로, 웨이트의 현재 크기와 업데이트로 인한 변화량의 크기를 비교해 볼 수도 있다. (Note: 그냥 날 것의 그라디언트 값이 아니라, 웨이트의 변화량이다 (이를테면 vanilla SGD에서는 학습 속도(learning rate)와 그라디언트의 곱이다).) 모든 파라미터(의 집합)마다 독립적으로 이 비율을 추적/계산하고 싶은가? 대충 짚자면 이 비율은 1e-3 근처여야 한다. 이보다 낮으면 학습 속도(learning rate)가 너무 낮은 것이다. 이보다 크면 학습 속도가 너무 크다. 특정한 예를 들자면 아래와 같다:
# assume parameter vector W and its gradient vector dW
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # simple SGD update
update_scale = np.linalg.norm(update.ravel())
W += update # the actual update
print update_scale / param_scale # want ~1e-3
최솟값이나 최댓값을 추적할 수도 있고, 그라디언트와 업데이트값의 놈(norm)을 계산하고 추적할 수도 있다. 이 지표들은 대개 연관성이 높아서 거의 비슷한 결과를 준다.
층별 활성값 및 그라디언트의 분포 (Activation / Gradient distributions per layer)
올바르지 않은 초기값 설정(initialization)은 학습 과정을 느리게 하거나 완전히 망칠 수 있다. 운좋게도 이 이슈는 상대적으로 쉽게 분석할 수 있다. 한 방법은 활성값/그라디언트값의 히스토그램을 망(network)의 모든 층(layer)마다 그려보는 것이다. 직관적으로 생각해 보면, 만일 이상한 분포가 나오면 좋은 징조가 아닐 수 있다 - 이를테면, tanh 뉴런(neuron)에서는 활성값이 [-1,1]의 전 범위에 걸쳐 분산되어 있는 모습을 보고 싶다. 혹시 모든 활성값이 0을 내놓거나 -1 혹은 1에 집중되어 있으면 문제가 있는 것이다.
첫번째 층의 시각화 (First-layer Visualizations)
마지막으로, 만일 당신이 이미지 픽셀에 관련된 일을 한다면 첫 층의 특징(feature)들을 시각화하는 것이 많은 도움이 될 수도 있다.


파라미터값의 업데이트 (Parameter updates)
수식적으로 그라디언트값은 역전파(backpropagation)으로 계산되고 이는 파라미터값 업데이트를 위해 사용된다. 업데이트를 수행하는 몇 접근법들이 있는데 후술하겠다.
딥 네트워크에서의 최적화 문제는 지금 가장 활발히 연구가 진행되고 있는 분야이다. 이 섹션에서는 (당신이 자주 보았을) 공통적으로 자주 쓰이는 테크닉과 그것들의 직관적인 아이디어를 살펴 본다. 디테일한 사항은 수업의 범위를 넘으므로 다루지 않는다. 흥미 있는 독자는 후에 등장할 몇 참고문헌을 봐도 좋다.
SGD와 그 외 (SGD and bells and whistles)
바닐라 업데이트 (Vanilla update). 가장 간단한 업데이트 형태는 그라디언트의 반대방향으로 파라미터를 업데이트하는 것이다(왜냐하면 그라디언트는 증가하는 방향을 가리키니까. 그렇지만 우리는 손실함수를 최소화하고 싶어한다). 파라미터의 벡터를 x라 하고 그라디언트를 dx라 쓰면, 가장 간단한 업데이트는 다음과 같:
# Vanilla update
x += - learning_rate * dx
여기서 학습속도 learning_rate 는 하이퍼파라미터(hyperparamter)이고 고정된 상수이다. 만일 dx가 전체 데이터셋에서 계산되고 학습 속도가 충분히 작을 때, 최소한 나쁜 프로세스는 아님을 보장한다.
모멘텀 업데이트 (Momentum update)는, 적어도 딥 네트워크에서는, 바닐라 업데이트보다 더 잘 수렴한다. 이 방법은 최적화 문제(optimization problem)를 물리학적 관점에서 바라보는 데서 유래했다. 자세히 말하자면, 손실함수는 구릉지대에서 높이에 해당한다 (그래서 포텐셜 에너지에도 대응되는데 이고 따라서 이다). 파라미터의 초기값을 임의로 정하는 것은 입자를 어떤 위치에서 0의 속도로 세팅하는 것과 똑같다. 이 상황에서 최적화 과정은 파라미터 벡터(즉 입자)를 ‘굴리는’ 과정과 동일하다 볼 수 있다.
입자에 작용하는 힘(force)은 포텐셜 에너지의 그라디언트 (즉 )와 관련되어 있으므로, 입자가 느끼는 힘은은 정확하게 손실함수의 그라디언트(의 반대부호)이다. 게다가 이므로 그 그라디언트(의 반대부호)는 입자에 작용하는 가속도에 비례한다. 위에서의 SGD와 다른 점을 발견했는가? SGD는 위치값(현재 파라미터값 - 역자주)에 그라디언트가 직접 합쳐진다. 모멘텀 업데이트는, 물리학적 관점에서, 그라디언트가 오직 속도(velocity)에만 직접적으로 영향을 주고 속도가 위치값(position)에 영향을 줄 것을 제안하고 있다:
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
여기서 우리는 새로운 변수 v를 도입하고 0으로 초기화했다. mu는 또 하나의 하이퍼파라미터(hyperparamter)이다.
정확한 용어는 아니지만 우리는 이 mu를 모멘텀(운동량)이라 부르기로 한다. (보통 0.9로 설정한다) 사실 마찰 계수라고 부르는 쪽이 더 mu에 맞기는 하다. 이 변수는 입자의 현재 속도 및 운동에너지를 효과적으로 감소시키도록 도와준다. 이게 없다면 아마 입자는 언덕의 아래쪽에 절대 멈추지 못할 것이다. 만약 모멘텀을 교차검증(cross-validation)으로 선택한다면 보통 [0.5, 0.9, 0.95, 0.99]로 설정한다. 에폭에 따라 모멘텀의 크기를 조정하면 최적화(optimization)에 더 이로울 수도 있다. 이를테면 시작할 때는 0.5의 모멘텀으로 시작하되 몇 번의 에폭을 지나면 0.99로 설정할 수도 있다. 이는 학습 속도의 스케줄을 담금질(annealing)하는 것과도 비슷하다. (뒤에 논의할 예정이다)
모멘텀 업데이트를 쓰면, (파라미터 벡터가 업데이트되는) 속도의 방향은 그라디언트들이 많이 향하는 방향으로 축적될 것이다.
최근에 많은 주목을 받은 Nesterov 모멘텀 (Nesterov Momentum) 은 모멘텀 업데이트와 조금 다르다. 볼록함수(convex function)에서는 이 업데이트가 강력한 이론적 성질을 갖고 있고, 실제상황에서도 보통의 모멘텀 방법론보다 (많은 경우에서) 조금 더 낫다고 한다.
Nesterov 모멘텀의 핵심 아이디어는 다음과 같다. 만약 현재 파라미터 벡터가 x라는 어떤 위치에 있다고 치고 위의 모멘텀 엄데이트를 보자. 만일 위의 integrate velocity 과정에서 뒷항없이 v = mu * v 만 있다고 가정하면, 다음 위치로 x + mu * v가 “예견”될 것이다. 그러므로 이전의/오래된 위치 x 대신 예견된 위치 x + mu * v에서 그라디언트를 계산하는 것이 합리적일 수 있다.
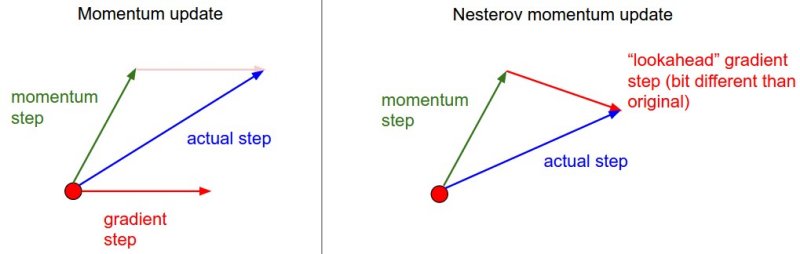
다른 말로 하면, 다음과 같이 계산한다. (notation이 조금 이상하다.)
x_ahead = x + mu * v
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead
x += v
실제 용례에서 사람들은 위 식을 재서술하여 바닐라 SGD나 이전의 모멘텀 업데이트의 꼴처럼 고칠 때가 있다. 이를테면 x_ahead = x + mu * v 부분을 손보고, 업데이트를 x의 관점이 아닌 x_ahead의 관점에서 서술하면 (그리고 x_ahead를 x로 고쳐쓰면) 아래와 같다. 사족을 달자면 이제 우리가 저장하는 파라미터 벡터는 언제나 “예견된” 버전이다.
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
위 식들의 출처와 Nesterov’s Accelerated Momentum의 수학적 서술에 대해 더 알아보고 싶으면 아래를 참조하라.
- Advances in optimizing Recurrent Networks by Yoshua Bengio, Section 3.5.
- Ilya Sutskever’s thesis (pdf) contains a longer exposition of the topic in section 7.2
학습 속도 담금질 (Annealing the learning rate)
깊은 신경망의 훈련에서 시간에 따라 훈련 속도를 담금질(anneal, 조정)하는 건 언제나 도움이 된다. 이 직관을 기억해 두면 도움이 된다: 높은 학습 속도에서는, 전체 시스템이 너무 높은 운동 에너지를 갖고 있어서 파라미터 벡터가 혼돈스럽게 튀고, (손실 함수의) 좁고 깊숙한 골짜기 안으로 쏙 들어가서 정착하기 힘들다.
그러면 학습 속도를 언제 줄일 것인가? 좀 tricky할 것이다. 우선 천천히 줄여봐라. 그러면 오랜 시간동안 거의 제자리에서 혼돈스럽게 왔다갔다 할 것이다. 그렇지만 너무 빨리 줄이면 전체 시스템이 너무 빨리 식을 것이고, 갈 수 있는 최적의 장소에 도달하지 못할 수 있다. 학습속도를 감소시키는 방법은 보통 다음 세 가지가 있다.
- 계단식 감소 (step decay): 몇 에폭마다 일정량만큼 학습 속도를 줄인다. 전형적으로는 5 에폭마다 반으로 줄이거나 20 에폭마다 1/10씩 줄이기도 한다. 이 숫자들은 전적으로 문제와 모형의 타입에 의존한다. 실전에서는, 우선 고정된 학습 속도로 검증오차(validation error)를 살펴보다가, 검증오차가 개선되지 않을 때마다 학습 속도를 감소시키는 (이를테면 0.5정도?) 방법을 택하기도 한다.
- 지수적 감소 (exponential decay)는 꼴을 뜻한다. 여기서 는 초모수(hyperparameter)이고 는 반복 횟수이다 (물론 에폭을 단위로 해도 된다.)
- 1/t 감소는 꼴을 뜻하고 여기서 는 초모수이고 는 반복 횟수이다.
실전에서는 계단식 감소 방식이 조금 더 선호될만 한데, 관련된 초모수들(몇 에폭마다 감소시킬지, 그리고 감소율)이 에 비해서 해석이 더 쉽기 때문이다. 마지막으로, 계산 자원이 충분하다면, 감소율을 좀 더 낮춰서 오랜 시간동안 (모형을) 훈련시켜라.
이차 근사 방법들 (Second order methods)
딥러닝의 맥락에서 두 번째로 대중적인 최적화 방법은 뉴턴 방법(Newton’s method)인데 다음과 같은 업데이트 방식을 뜻한다:
여기서 는 헤시안 행렬(Hessian matrix)로, (다변수 함수의) 2차 미분으로 이루어진 정방행렬을 뜻한다. 항은 (그라디언트 감소 Gradient Descent에서 보았던) 그라디언트 벡터이다. 직관적으로 헤시안 행렬은 어떤 함수의 국지적인 곡률(curvature)을 뜻하고 이 정보로 울이는 더 효율적인 업데이트를 수행할 수 있다. 특별히, 헤시안 행렬의 역행렬을 곱함으로써, 휨이 약한 방향으로는 더 공격적으로 그리고 휨이 강한 방향으로는 짧게짧게 움직일 수 있다. 일차 근사 방법에 비해 뉴턴 방법이 가지는 강점은, 위의 업데이트 공식을 보면 학습 속도(learning rate)에 대한 초모수(hyperparameter)가 없다는 것이다.
그렇지만 위의 업데이트는 거의 모든 실제 상황에서는 쓸모가 없는 게, 공식 그대로(explicitly) 헤시안 행렬을 계산한다면 (역행렬을 취하는 일 포함하여) 상상도 못할 시간과 메모리가 필요하다. 예를 들면, 모수가 백만개 정도인 신경망은 [1,000,000 x 1,000,000] 크기의 헤시안 행렬을 필요로 하고 이는 3725GB의 램(RAM)을 필요로 한다. 그 결과로 다양한 유사-뉴턴 방법이 역-헤시안 행렬을 근사하기 위해 고안되었다. 이 방법론들 중 L-BFGS가 가장 대중적이다. L-BFGS는 시간(iteration)에 따른 그라디언트의 변화를 (간접적으로) 근사에 이용한다. 즉, 전체 행렬은 절대 계산되지 않는다.
그렇다고 해도, 메모리 걱정을 없앴다고 할지라도, L-BFGS를 그냥 적용하자면 큰 단점이 하나 있는데 바로 전체 훈련 집합(traning set) 전체를 대상으로 계산하여야 한다는 점이다. 수백만 개체가 있는 그 데이터셋 말이다. 배치(Batch)-SGD와는 달리, 미니배치(mini-batch)에서 L-BFGS가 작동하게 하는 방법은 좀더 꼼수를 필요로 하며 활발한 연구 분야이다.
실제 상황에서는, 지금까지는, L-BFGS나 다른 이차 근사 방법이 대규모 딥러닝이나 CNN에서 사용되지는 않는 게 보통이다. 표준적으로는 SGD와 그 변종들 (모멘텀이나 Nesterov’s 모멘텀)이 훨씬 간단하고 계산도 빨라서 많이 사용된다.
추가 참고문헌:
- Large Scale Distributed Deep Networks은 Google Brain team이 출판하였다. 대규모 분산 최적화 (large-scale distributed optimization)에서 L-BFGS와 SGD(의 변형 방법론들)을 비교하였다.
- SFO 알고리즘은 SGD와 L-BFGS의 장점을 혼합하고자 노력하였다.
파라미터별 데이터-맞춤 학습 속도 (Per-parameter adaptive learning rates)
지금까지 논의된 접근법들은 모든 파라미터에 똑같은 학습 속도를 적용하였다. 학습 속도의 튜닝(tuning)은 계산이 많은(expensive) 작업인지라, 데이터에 맞추어(adaptively) 자동으로 학습 속도를 정하는 방법을 찾고자 많은 사람들이 노력하였다. 파라미터별로 학습 속도를 다르게 하고 이를 데이터-맞춤으로 정하려는 노력들 또한 있었다. 이러한 방법들은 보통 또다른 초모수(hyperparameter) 세팅이 필요하긴 하지만, 이 초모수는 넓은 범위에서 잘 작동하는 편이라 일반적인 학습 속도 튜닝보다는 덜 까다롭다. 이번 절에서는 실전에서 마주칠 수도 있는 주요 데이터-맞춤 방법들을 조망해본다:
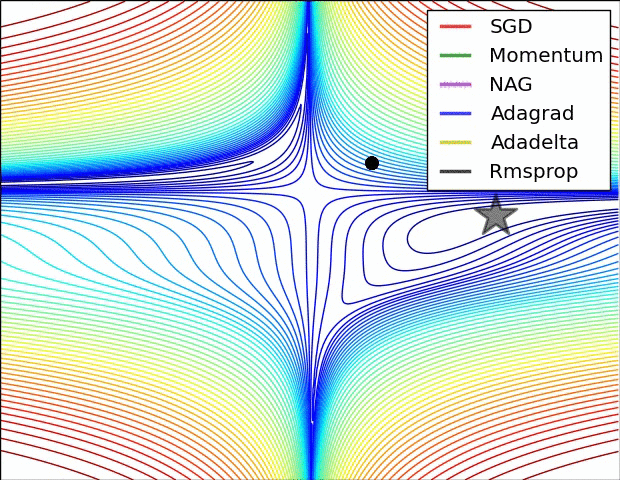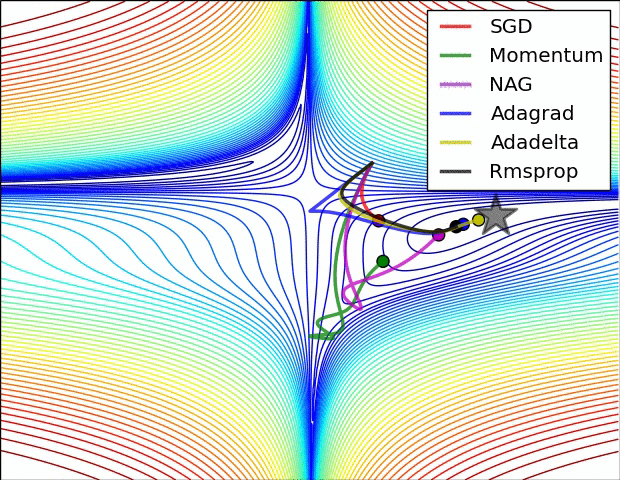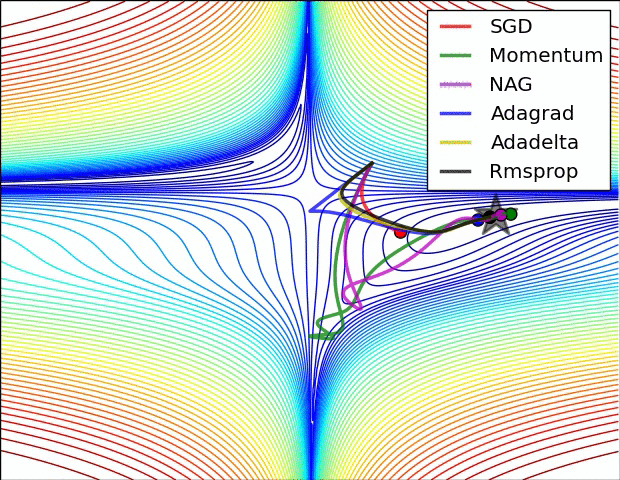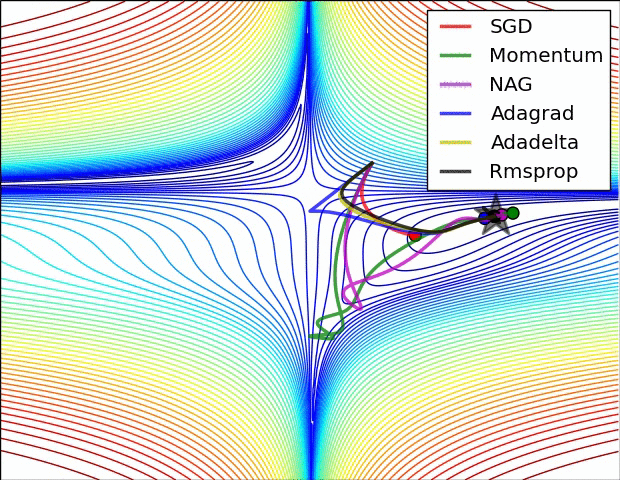
Adagrad는 데이터-맞춤 학습속도 조정 방법 중 하나이고 Duchi et al. 에서 처음 제안되었다.
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
위에서 변수 cache는 그라디언트 벡터의 사이즈와 동일한 사이즈를 갖고 있다. cache의 각 성분은 (해당 성분에 대응하는) 그라디언트의 제곱값들을 계속 추적하고 있고, 파라미터 업데이트에서, 성분별로, 일종의 표준화 기능을 수행한다. 주목할 점은, 높은 그라디언트값을 갖는 웨이트값(weight)들은 점점 실질적인 학습속도(effective learning rate)가 감소하고 / 그라디언트 값이 낮거나 업데이트가 거의 없는 웨이트값들은 실질 학습속도가 증가한다는 것이다. 놀랍게도 제곱근(square root) 연산이 여기서 중요한 비중을 차지한다. 제곱근이 없다면 알고리즘의 성능이 많이 나빠진다. 변수 eps는 분모가 너무 0에 가깝지 않도록 안정화 역할을 하고 주로 1e-4에서 1e-8의 값이 할당된다. Adagrad의 단점이 있다면, 딥러닝의 경우에는, 학습 속도가 단조적이라 너무 한 방향으로 급진적(aggressive)으로 나가거나, 혹은 학습을 너무 빨리 멈출 가능성도 있다.
RMSprop. RMSprop는 매우 효과적이지만 아직 출판되지 않은 데이터-맞춤 학습속도 조정 방법이다. 현재는 Geoff Hinton의 Coursera 강의 중 다음 슬라이드를 인용한다: slide 29 of Lecture 6 (역자 주: 2016년 8월 현재에도 검색결과 논문을 찾지는 못하였습니다. Goodfellow et al.의 책 [
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
여기서 decay_rate는 초모수이고 보통 [0.9, 0.99, 0.999] 중 하나의 값을 취한다. 주목할 점은 += 업데이트는 Adagrad와 동등하지만, cache가 “어디선가 샌다”. 따라서 RMSProp은 여전히 각 웨이트값을 (그것의 과거 그라디언트) 값으로) 조정하여 성분별로 실질 학습속도를 비슷하게 만드는 효과는 갖고 있지만, Adagrad처럼 학습 속도가 단조적으로 줄지는 않는다.
Adam. Adam은 최근에 제안된 방법인데 RMSProp에 모멘텀(momentum)을 혼합한 것처럼 보인다. 간단하게 쓰면 업데이트는 다음과 같다:
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)
업데이트는 RMSProp의 업데이트 방식과 정확히 같아 보이는데, 그냥 (노이즈가 껴있을 수도 있는) 그라디언트 dx 대신에 “안정화된” 버전인 m이 사용되었다는 점이 다르다. 논문에 따르면 추천되는 초모수값들은 eps = 1e-8, beta1 = 0.9, beta2 = 0.999이다. 실전에서 Adam은 기본 알고리즘으로 추천되고 있고, 가끔은 RMSProp보다 조금 더 잘 하기도 한다. 그러나 SGD+Nesterov Momentum도 대안으로 해볼만 하다. Adam 업데이트 절차에는 편향 보정(bias correction) 매커니즘이 반영되어 있는데, 벡터 m,v가 나중에 완벽하게 “워밍업” 되기 전에 (iteration의 처음 몇 스텝에서) 초기화되어 0에 편향되어 있다는 점을 보상하기 위해서이다. 자세한 사항은 논문이나 강의 코스 슬라이드를 참조하라.
추가 참고문헌:
- Unit Tests for Stochastic Optimization는 (지금까지 제안된) 확률적 최적화(stochastic optimization) 방법들을 평가하는 표준적인 테스트들을 제안하고 있다.
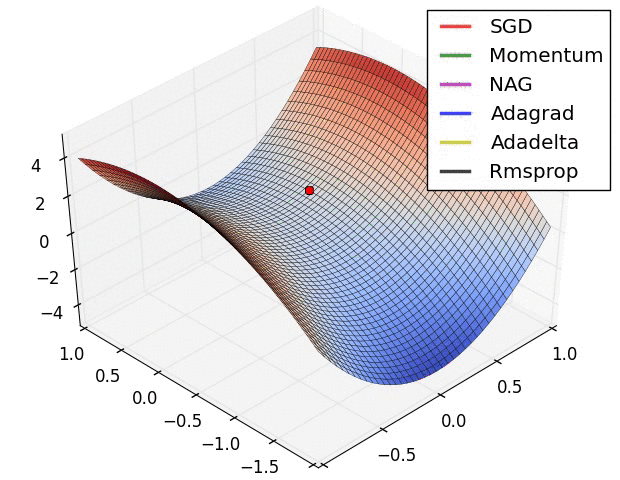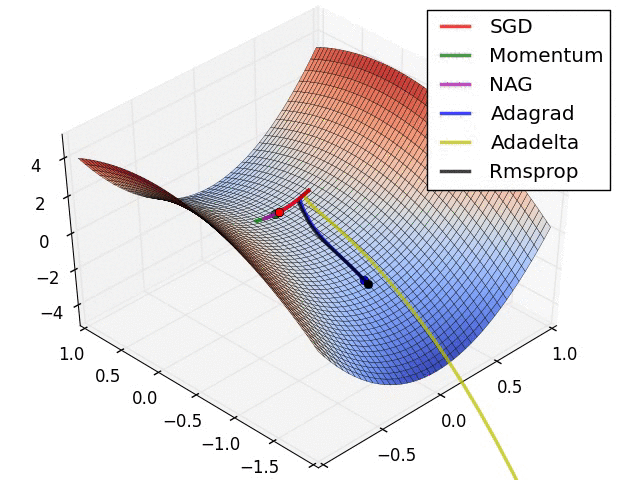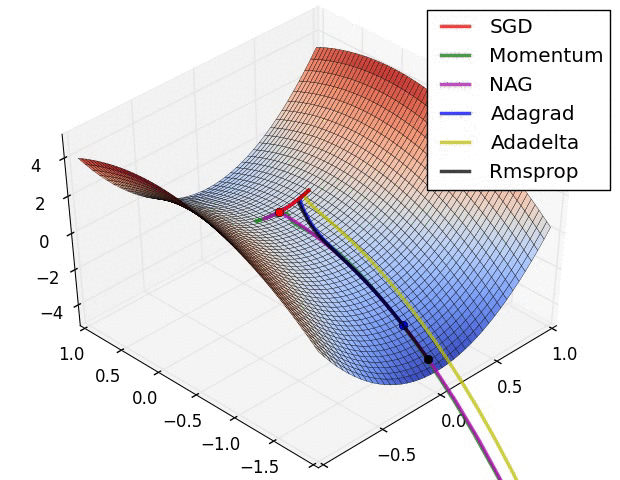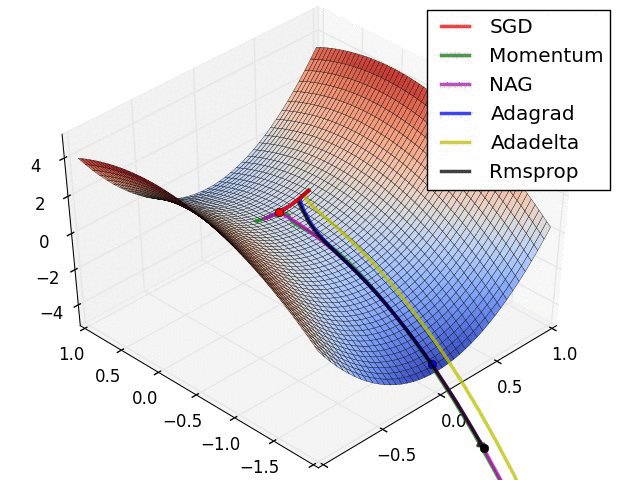
초모수 최적화 (Hyperparameter optimization)
일전에 본 대로, 신경망(neural network)의 훈련에는 많은 초모수(hyperparamter) 설정이 관련된다. 신경망 관련 논의에서 가장 빈번하게 등장하는 초모수는 다음과 같다:
- 학습속도의 초기값(the initial learning rate)
- 학습속도 경감 계획, 이를테면 경감 상수 (learning rate decay schedule (such as the decay constant))
- L2나 드랍아웃 페널티의 정규화 강도 (regularization strength (L2 penalty, dropout strength))
그렇지만 역시 본 대로, 덜 민감한 초모수들도 있는데, 이들은 파라미터별 데이터-맞춤 학습 방법, 모멘텀이나 관련 스케쥴 등에서 등장하였다. 이번 절에서는 초모수 최적화를 수행하기 위한 추가적인 팁이나 트릭들을 언급한다:
코드 구성 단계에서 (Implementation). 큰 신경망은 대개 긴 학습시간이 걸리고, 따라서 초모수 검색에는 며칠, 몇 주가 걸릴 수도 있다. 코드를 짤 때 이 점을 염두에 두는 것이 중요하다 (코드 베이스의 구성이 달라질 수도 있다). 하나 가능한 코드 구성은, 초모수를 임의로 선택하여 최적화를 수행하는 일꾼을 만드는 것이다. 이 일꾼에게 훈련 과정에서 매 에폭 뒤의 검증 성능을 쭉 추적하여 모형의 체크포인트들을 (다른 훈련 통계량들, 이를테면 시간에 따른 손실함수값들과 함께) 파일에 저장케 하라. 공유 파일 시스템 위에 저장하면 더 좋다. 검증 성능을 아예 직접 파일 이름에 써 놓는 것도 괜찮다. 그러면 과정이 더 단축되고 단순할 것이다. 그리고 마스터라 불릴 두번째 프로그램을 만들어서 계산 클러스터별로 일꾼들을 개시(launch)하거나 끝내(kill)게 하라. 혹은 마스터는 일꾼이 작성한 체크포인트들을 조사하고 훈련 통계량들로 그림을 그릴 수도 있다.
교차검증보다는 단일한 검증 집합 (Prefer one validation fold to cross-validation). 많은 경우에, 적당한 크기의 검증 집합을 설정해 두어 한 번만 검증하는 것이, 여러 번의 교차검증보다 코드를 단순화시킨다. 사람들이 “교차검증” 했다고 얘기해도, 많은 경우에 그 사람들은 단일한 검증 집합만 썼을 것이다.
초모수의 범위 (Hyperparameter ranges). 로그 스케일로 초모수를 찾아라. 예를 들어, 학습 속도의 선정은 전형적으로 다음과 같이 보일 수도 있다: learning_rate = 10 ** uniform(-6, 1). 다시 말하면, 균등분포에서 난수를 뽑은 뒤에 이를 10의 제곱값으로 취하는 것이다. 같은 전략이 정규화 강도 검색에도 사용되어야 한다. 왜냐고? 직관적으로, 학습 속도와 정규화 강도는 학습 동역학에 배수적인(multiplicative) 효과가 있기 때문이다 - 학습 속도는 업데이트에서 그라디언트에 곱해지는 수이다. 이를테면, 최초 학습 속도가 0.001이면 이를 0.01씩 더할 경우 동역학에 큰 영향을 미치지만 최초 학습 속도가 10인 경우에는 거의 영향이 없다. 그러므로 학습 속도의 범위는 어떤 값을 계속 곱하거나 나누는 것이 (빼거나 더하는 것보다) 더 자연스럽다. 대신에, 어떤 초모수들(이를테면 드랍아웃)은 보통의 스케일에서 검색된다. (예. dropout = uniform(0,1)).
그리드 검색보다는 임의 검색 (Prefer random search to grid search)은 Bergstra and Bengio가 쓴 다음 논문에서 논의되었다: Random Search for Hyper-Parameter Optimization, “randomly chosen trials are more efficient for hyper-parameter optimization than trials on a grid”. 그리고 밝혀진 대로, 이게 더 구현하기 쉽다.
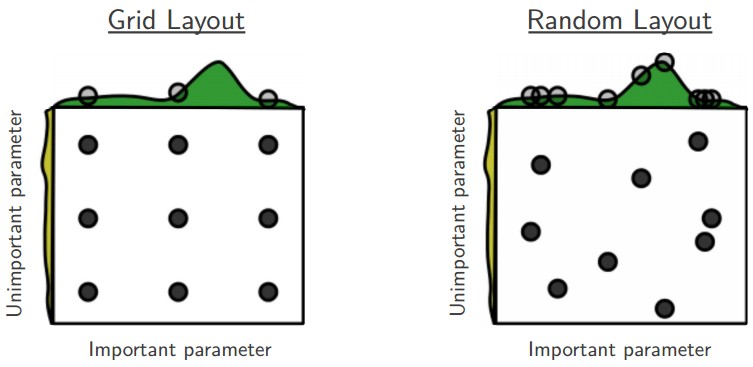
가장 좋은 값이 경계에 있으면 조심하라 (Careful with best values on border). 가끔은 초모수 검색 범위 (이를테면 학습 속도) 가 나쁘게 설정되었을 수도 있다. 이를테면, learning_rate = 10 ** uniform(-6, 1)을 사용한다고 가정하여 보자. 한번 결과를 받았으면, 최종 학습 속도가 이 구간의 끝에 있지 않아야 한다. 그렇지 않으면, 당신은 (구간 밖에 있는) 더 최적의 초모수를 놓치고 있을는지도 모른다.
성긴 검색에서 촘촘한 검색으로 (Stage your search from coarse to fine). 실전에서는, 처음에는 널찍한 범위에서 검색을 하다가 (예. 10 ** [-6, 1]), 좋은 결과가 어디에서 발생하냐에 따라 범위를 좁힐 수도 있다. 또한, 처음의 성긴 검색에서는 1 에폭이나 혹은 더 적게만 훈련하는 게 도움이 될 수도 있는데, 왜냐하면 많은 초모수 세팅에서는 하나도 학습하는 게 없을 수도 있거나 즉시 무한대의 손실함수값으로 폭발할 수도 있기 때문이다. 두 번째 단계는 좀더 좁은 범위에서의 검색을, 5 에폭 정도로, 할 수 있을 것이다. 그리고 마지막 검색에서는 좁은 범위에서 많은 에폭의 훈련을 수행해도 좋겠다.
베이지안 초모수 최적화 (Bayesian Hyperparameter Optimization)는 초모수 공간을 좀 더 효율적으로 항해하는 방법을 고안하기 위한 분야이다. 핵심 아이디어는 초모수들의 성능을 평가할 때 탐험(exploration)-개발(exploitation)의 상충(trade-off)에서 적절한 균형을 찾는 것이다. 많은 라이브러리들이 이 모형에 기반하여 개발되었고 그 중에 잘 알려진 것은 Spearmint, SMAC, 그리고 Hyperopt이다. 그러나, ConvNet 관련된 실전 세팅에서는 아직 조심스레 선택된 구간에서의 임의 검색이 상대적으로 더 뛰어나다. 딥러닝의 최전선 참호에서(from-the-trenches) 진행중인 논의를 참조하라. here.
평가
모형 앙상블 (Model Ensembles)
실전에서, 신경망(neural network)의 성능을 몇 퍼센트 끌어올릴 수 있는 믿을 만한 방법이 하나 있는데 바로 여러 개의 독립적인 모형을 만들고 테스트 때 그들의 평균 예측을 취하는 것이다. 앙상블에 관여하는 모형이 많아지면, 보통 성능은 단조적으로 개선된다 (비록 개선 정도가 점점 떨어질지라도). 게다가, 앙상블 내에서 모형의 다양함이 늘어날수록 성능의 개선은 더 극적이다. 아래는 앙상블을 구축하는 몇 가지 방법이다:
- 같은 모형, 다른 초기화 (Same model, different initializations). 교차 검증으로 최고의 초모수를 결정한 다음에, 같은 초모수를 이용하되 초기값을 임의로 다양하게 여러 모형을 훈련한다. 이 접근법의 위험은, 모형의 다양성이 오직 다양한 초기값에서만 온다는 것이다.
- 교차 검증 동안 발견되는 최고의 모형들 (Top models discovered during cross-validation). 교차 검증으로 최고의 초모수(들)를 결정한 다음에, 몇 개의 최고 모형을 선정하여 (예. 10개) 이들로 앙상블을 구축한다. 이 방법은 앙상블 내의 다양성을 증대시키나, 준-최적 모형을 포함할 수도 있는 위험이 있다. 실전에서는 이를 수행하는 게 (위보다) 쉬운 편인데, 교차 검증 뒤에 추가적인 모형의 재훈련이 필요없기 때문이다.
- 한 모형에서 다른 체크포인트들을 (Different checkpoints of a single model). 만약 훈련이 매우 값비싸면, 어떤 사람들은 단일한 네트워크의 체크포인트들을 (이를테면 매 에폭 후) 앙상블하여 제한적인 성공을 거둔 바 있음을 기억해 두라. 명백하게 이 방법은 다양성이 떨어지지만, 실전에서는 합리적으로 잘 작동할 수 있다. 이 방법은 매우 간편하고 저렴하다는 것이 장점이다.
- 훈련 동안의 모수값들에 평균을 취하기 (Running average of parameters during training). 훈련 동안 (시간에 따른) 웨이트 값들의 지수 하강 합(exponentially decaying sum)을 저장하는 제 2의 네트워크를 만들면 언제나 몇 퍼센트의 이득을 값싸게 취할 수 있다. 이 방식으로 당신은 최근 몇 iteration 동안의 네트워크에 평균을 취한다고 생각할 수도 있다. 마지막 몇 스텝 동안의 웨이트값들을 이렇게 “안정화” 시킴으로써 당신은 언제나 더 나은 검증 오차를 얻을 수 있다. 거친 직관으로 생각하자면, 목적함수는 볼(bowl)-모양이고 당신의 네트워크는 극값(mode) 주변을 맴돌 것이므로, 평균을 취하면 극값에 더 가까운 어딘가에 다다를 기회가 더 많아질 것이다.
모형 앙상블의 단점이 하나 있다면 테스트 샘플에 모형을 적용할 때 평가(evaluation)에 더 시간이 걸린다는 점이다. 흥미로운 독자는 Geoff Hinton의 “Dark Knowledge”에서 영감을 얻을 수도 있겠다. 여기서의 아이디어는 좋은 앙상블 모형을 하나의 모형으로 “증류”하는 것인데, 앙상블 모형의 로그-가능도(log-likelihood)를 어떤 변형된 목적함수로 통합하는 작업과 관련이 있다.
요약 (Summary)
신경망(neural network)를 훈련하기 위하여:
- 코드를 짜는 중간중간에 작은 배치로 그라디언트를 체크하고, 뜻하지 않게 튀어나올 위험을 인지하고 있으라.
- 코드가 제대로 돌아가는지 확인하는 방법으로, 손실함수값의 초기값이 합리적인지 그리고 데이터의 일부분으로 100&%의 훈련 정확도를 달성할 수 있는지 확인하라.
- 훈련 동안, 손실함수와 훈련/검증 정확도를 계속 살펴보고, (이게 좀 더 멋져 보이면) 현재 파라미터 값 대비 업데이트 값 또한 살펴보라 (대충 ~1e-3 정도 되어야 한다). 만약 ConvNet을 다루고 있다면, 첫 층의 웨이트값도 살펴보라.
- 업데이트 방법으로 추천하는 건 SGD+Nesterov Momentum 혹은 Adam이다.
- 학습 속도를 훈련 동안 계속 하강시켜라. 예를 들면, 정해진 에폭 수 뒤에 (혹은 검증 정확도가 상승하다가 하강세로 꺾이면) 학습 속도를 반으로 깎아라.
- 초모수 검색은 그리드 검색이 아닌 임의 검색으로 수행하라. 처음에는 성긴 규모에서 탐색하다가 (넓은 초모수 범위, 1-5 에폭 정도만 학습), 점점 촘촘하게 검색하라 (좁은 범위, 더 많은 에폭에서 학습).
- 추가적인 개선을 위하여 모형 앙상블을 구축하라.
추가 참고문헌
- SGD tips and tricks from Leon Bottou
- Efficient BackProp (pdf) from Yann LeCun
- Practical Recommendations for Gradient-Based Training of Deep Architectures from Yoshua Bengio
번역: 최영근 ygchoistat