Recurrent Neural Network (RNN) Tutorial - Part 1
WildML이라는 블로그에 RNN에 관련된 좋은 튜토리얼(영어)이 있어서 번역해 보았습니다. 중간중간에 애매한 용어들은 그냥 영어로 남겨놓았는데, 번역이 이상한 부분을 발견하셨거나 질문이 있으시면 댓글로 알려주까세요!
RNN은 다양한 자연어처리(NLP) 문제에 대해 뛰어난 성능을 보이고 있는 인기있는 모델이다. 하지만 최근의 인기에 비해 실제로 RNN이 어떻게 동작하는지, 어떻게 구현해야 하는지에 대해 쉽게 설명해놓은 자료는 상당히 부족한 편이다. 따라서 이 튜토리얼에서는 아래 내용을 하나하나 자세히 다루고자 한다.
- Introduction to RNNs (현재 포스트)
- Python과 Theano를 이용한 RNN 구현 방법
- Backpropagation Through Time (BPTT) 알고리즘과 vanishing gradient 문제 이해하기
- RNN부터 LSTM 네트워크까지
본 튜토리얼의 일환으로 RNN 기반의 언어 모델을 구현할 것이다. 언어 모델은 두 가지로 응용될 수 있는데, 첫째로는 실제 세상에서 어떤 임의의 문장이 존재할 확률이 어느 정도인지에 대한 스코어를 매길 수 있다는 점이다. 이는 문장이 문법적으로나 의미적으로 어느 정도 올바른지 측정할 수 있도록 해주고, 보통 자동 번역 시스템의 일부로 활용된다. 두 번째는 새로운 문장의 생성이다 (이쪽이 훨씬 더 재밌는 응용 분야라고 생각). 셰익스피어의 소설에 언어 모델을 학습시키면 셰익스피어가 쓴 글과 비슷한 글을 네트워크가 자동으로 생성해 낸다. RNN 기반의 character-level 언어 모델이 생성해낼 수 있는 여러 가지 재밌는 데모를 Andrej Karpathy의 블로그 포스트에서 확인할 수 있다.
이 튜토리얼은 기본적인 신경망 구조(Neural Network)에 대해서 어느 정도의 이해가 있다고 가정하고 쓴 것이다. 만약 recurrent하지 않은 좀 더 기초적인 신경망 구조부터 공부하려면 Implementing A Neural Network From Scratch (원글과 같은 블로그에 있는 다른 포스트) 부터 보면 대략적인 개념과 구현에 대한 부분을 이해할 수 있을 것이다.
RNN이란?
RNN에 대한 기본적인 아이디어는 순차적인 정보를 처리한다는 데 있다. 기존의 신경망 구조에서는 모든 입력(과 출력)이 각각 독립적이라고 가정했지만, 많은 경우에 이는 옳지 않은 방법이다. 한 예로, 문장에서 다음에 나올 단어를 추측하고 싶다면 이전에 나온 단어들을 아는 것이 큰 도움이 될 것이다. RNN이 recurrent 하다고 불리는 이유는 동일한 태스크를 한 시퀀스의 모든 요소마다 적용하고, 출력 결과는 이전의 계산 결과에 영향을 받기 때문이다. 다른 방식으로 생각해 보자면, RNN은 현재지 계산된 결과에 대한 "메모리" 정보를 갖고 있다고 볼 수도 있다. 이론적으로 RNN은 임의의 길이의 시퀀스 정보를 처리할 수 있지만, 실제로는 비교적 짧은 시퀀스만 효과적으로 처리할 수 있다 (이 부분은 나중 파트에서 더 다룰 예정). 일반적인 RNN 구조는 다음과 같이 생겼다.
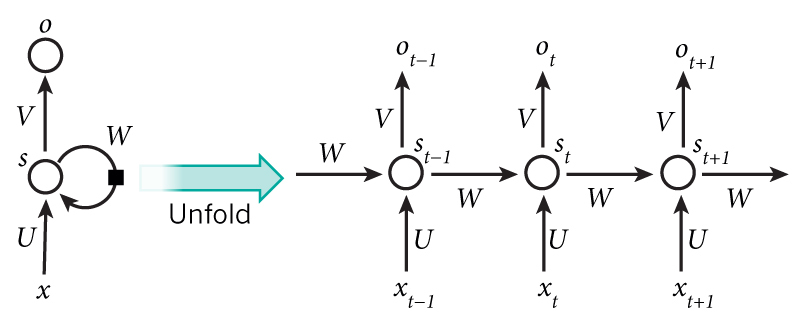
위 그림에서 RNN의 recurrent한 연결이 펼쳐진 것을 볼 수 있다. RNN 네트워크를 "펼친다"는 말은 간단히 말해서 네트워크를 전체 시퀀스에 대해 그려놓았다고 보면 된다. 즉, 우리가 관심있는 시퀀스 정보가 5개의 단어로 이루어진 문장이라면, RNN 네트워크는 한 단어당 하나의 layer씩 (recurrent 연결이 없는, 또는 사이클이 없는) 5-layer 신경망 구조로 펼쳐질 것이다. RNN 구조에서 일어나는 계산에 대한 식은 아래와 같다.
는 시간 스텝(time step)
에서의 입력값이다.
는 시간 스텝
. 비선형 함수
는 보통 tanh나 ReLU가 사용되고, 첫 hidden state를 계산하기 위한
은 보통 0으로 초기화시킨다.
는 시간 스텝

몇 가지 짚어두고 넘어갈 점이 있다.
- Hidden state
- 각 layer마다의 파라미터 값들이 전부 다 다른 기존의 deep한 신경망 구조와 달리, RNN은 모든 시간 스텝에 대해 파라미터 값을 전부 공유하고 있다 (위 그림의 U, V, W). 이는 RNN이 각 스텝마다 입력값만 다를 뿐 거의 똑같은 계산을 하고 있다는 것을 보여준다. 이는 학습해야 하는 파라미터 수를 많이 줄여준다.
- 위 다이어그램에서는 매 시간 스텝마다 출력값을 내지만, 문제에 따라 달라질 수도 있다. 예를 들어, 문장에서 긍정/부정적인 감정을 추측하고 싶다면 굳이 모든 단어 위치에 대해 추측값을 내지 않고 최종 추측값 하나만 내서 판단하는 것이 더 유용할 수도 있다. 마찬가지로, 입력값 역시 매 시간 스텝마다 꼭 다 필요한 것은 아니다. RNN에서의 핵심은 시퀀스 정보에 대해 어떠한 정보를 추출해 주는 hidden state이기 때문이다.
RNN으로 무엇을 할 수 있을까?
RNN은 많은 자연어처리 문제에서 성공적으로 적용되었다. 현재 전세계에서 RNN의 여러 종류 중에서 가장 많이 사용되는 것은 LSTM으로, 위에서 살펴본 기본 RNN 구조에 비해 더 긴 시퀀스를 효과적으로 잘 기억하기 때문이다. LSTM에 대해서는 나중 튜토리얼에서 더 자세히 다루겠지만, 우선은 대략적으로 hidden state를 계산하는 방법만 조금 다를뿐, RNN과 기본적으로는 같다고 생각하면 될 것이다. 아래에 RNN을 자연어처리 분야에 응용한 몇 가지 예시를 살펴보았다.
언어 모델링과 텍스트 생성
언어 모델은 주어진 문장에서 이전 단어들을 보고 다음 단어가 나올 확률을 계산해주는 모델이다. 언어 모델은 어떤 문장이 실제로 존재할 확률이 얼마나 되는지 계산해주기 때문에, 자동 번역의 출력값으로 어떤 문장을 내보내는 것이 더 좋은지 (실생활에서 높은 확률로 존재하는 문장들은 보통 문법적/의미적으로 올바르기 때문) 알려줄 수 있다. 문장에서 다음 단어가 나타날 확률을 계산해주는 주 목적 외의 부수적인 효과로 생성(generative) 모델을 얻을 수 있는데, 출력 확률 분포에서 샘플링을 통해 문장의 다음 단어가 무엇이 되면 좋을지 정한다면 기존에 없던 새로운 문장을 생성할 수 있다. 또한, 학습 데이터에 따라 다양하고 재밌는 여러 가지를 만들어낼 수도 있다. 언어 모델에서의 입력값은 단어들의 시퀀스 (e.g. one-hot encoded 벡터 시퀀스)이고, 출력은 추측된 단어들의 시퀀스이다. 네트워크를 학습할 때에는 시간 스텝 
언어 모델링 및 텍스트 생성에 관련된 연구 논문들:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
자동 번역 (기계 번역)
기계 번역 문제는 입력이 단어들의 시퀀스라는 점에서 언어 모델링과 비슷하지만, 출력값이 다른 언어로 되어있는 단어들의 시퀀스라는 점에서 차이가 있다. 네트워크 상에서의 중요한 차이점은, 입력값을 전부 다 받아들인 다음에서야 네트워크가 출력값을 내보낸다는 점에 있는데, 번역 문제에서는 어순이 다른 문제 등이 있기 때문에 대상 언어의 문장의 첫 단어를 알기 위해선 번역할 문장 전체를 봐야 할 수도 있기 때문이다.
번역에 관련된 연구 논문들:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
음성 인식
사운드 웨이브의 음향 신호(acoustic signal)를 입력으로 받아들이고, 출력으로는 음소(phonetic segment)들의 시퀀스와 각각의 음소별 확률 분포를 추측할 수 있다.
음성 인식 관련 연구 논문:
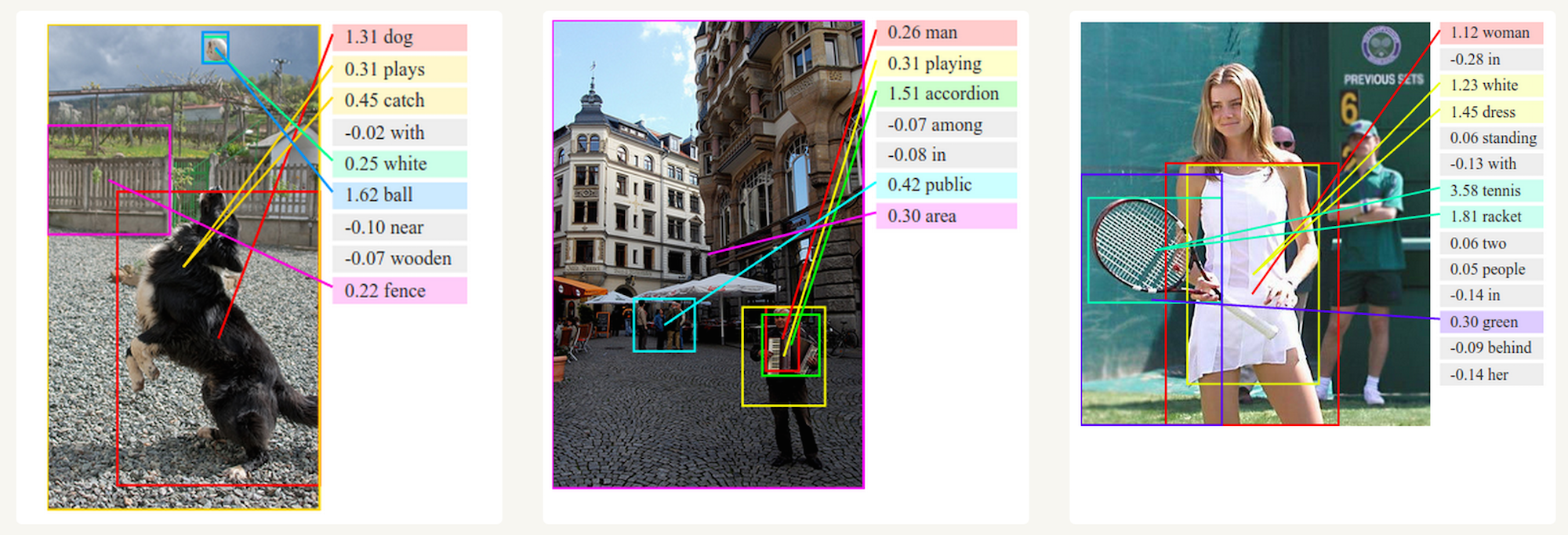
이미지 캡션 생성
컴퓨터 비젼에서 활발하게 사용된 convolutional neural network(CNN)과 RNN을 함께 사용한다면, 임의의 이미지를 텍스트로 설명해주는 시스템을 만드는 것도 가능하다. 실제로 어떻게 왜 동작하는지는 상당히 신기하다. CNN과 RNN을 합친 모델은 이미지로부터 얻어낸 주요 단어들과 이미지의 각 부분을 매칭해줄 수도 있다.
RNN 학습하기
RNN 네트워크를 학습하는 것은 기존의 신경망 모델 학습과 매우 유사하다. 네트워크의 각 시간 스텝마다 파라미터들이 공유되기 때문에 펼쳐진 네트워크에서 기존의 backpropagation 알고리즘을 그대로 사용하진 못하고 Backpropagation Through Time (BPTT)라는 약간 변형된 알고리즘을 사용한다. 그 이유는, 각 출력 부분에서의 gradient가 현재 시간 스텝에만 의존하지 않고 이전 시간 스텝들에도 의존하기 때문이다. 즉, t=4에서의 gradient를 계산하기 위해서는 시간 스텝 3개 이전부터 gradient를 전부 더해주어야 한다. 이 부분에 대해서는 나중 포스트에서 더 자세히 다룰 것이므로 잘 이해가 가지 않더라도 괜찮지만, vanishing/exploding gradient라는 문제 등에 의해서 단순한 RNN을 BPTT로 학습시키는 것은 긴 시퀀스를 다루기 어렵다는 정도로만 알아두자. 이를 해결하기 위한 여러 트릭들이 존재하고, LSTM 등 이 문제를 해결하기 위한 다양한 변종(확장된) RNN 모델들도 존재한다.
RNN - 확장된 모델들
RNN의 기본 모델의 여러 단점들을 보완하기 위해 여러 정교한 변화를 준 RNN 모델들이 연구되었다. 이에 대해서는 나중 포스트에서 보다 더 자세히 다루겠지만, 이 섹션에서 대략적인 소개를 하고 넘어갈까 한다.
Bidirectional RNN은 시간 스텝
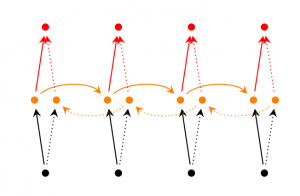
Deep (Bidirectional) RNN은 위 구조와 비슷하지만, 매 시간 스텝마다 여러 layer가 있다. 실제 구현에서는 이러한 구조가 학습할 수 있는 capacity가 크다 (당연히, 학습 데이터는 훨씬 더 많이 필요하다).
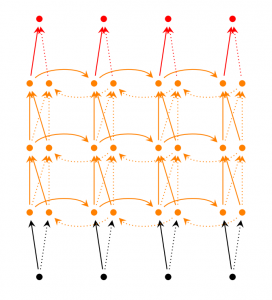
LSTM 네트워크는 최근에 매우 인기있는 구조로 앞서 잠깐 언급한 바 있다. LSTM은 RNN에 비해 본질적으로 다른 구조를 갖고 있다고 하긴 힘들지만, hidden state를 계산하는데 다른 식을 사용한다. LSTM에서는 RNN의 뉴런 대신에 메모리 셀이라고 불리는 구조를 사용하는데, 입력값으로 이전 state 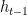
결론
우선 여기까지 RNN에 대한 기본 개념과 응용 분야에 어떤 것들이 있는지 살펴보았고, 다음 포스트에서는 Python과 Theano를 활용해서 간단한 RNN 언어 모델을 구현해볼 것입니다. 질문 및 조언을 댓글로 달아주세요!
번역: 최명섭